Semantic technologies in practice: Designing, building and exploiting knowledge graphs at Ontotext
2018-10-31
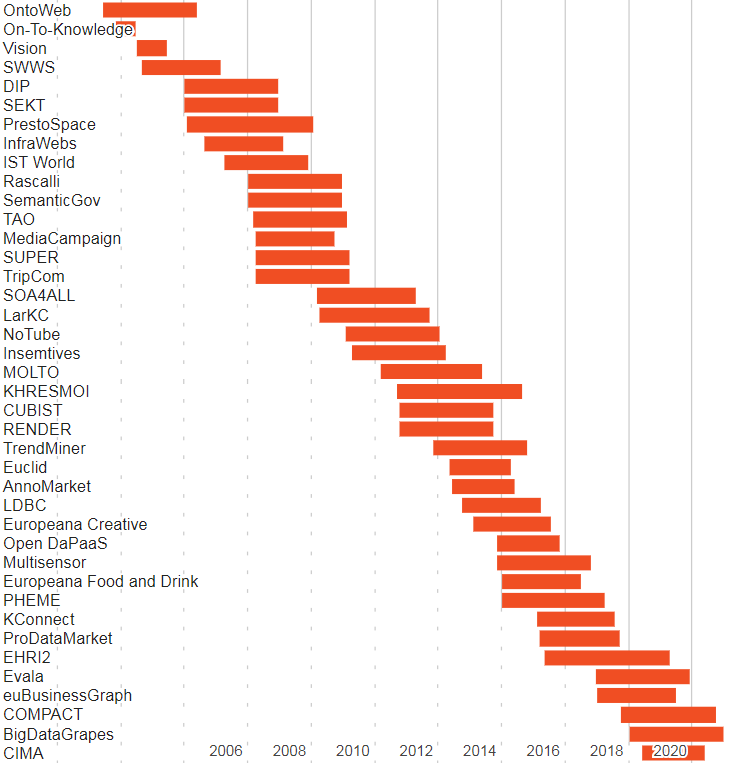
1.2 Research Projects
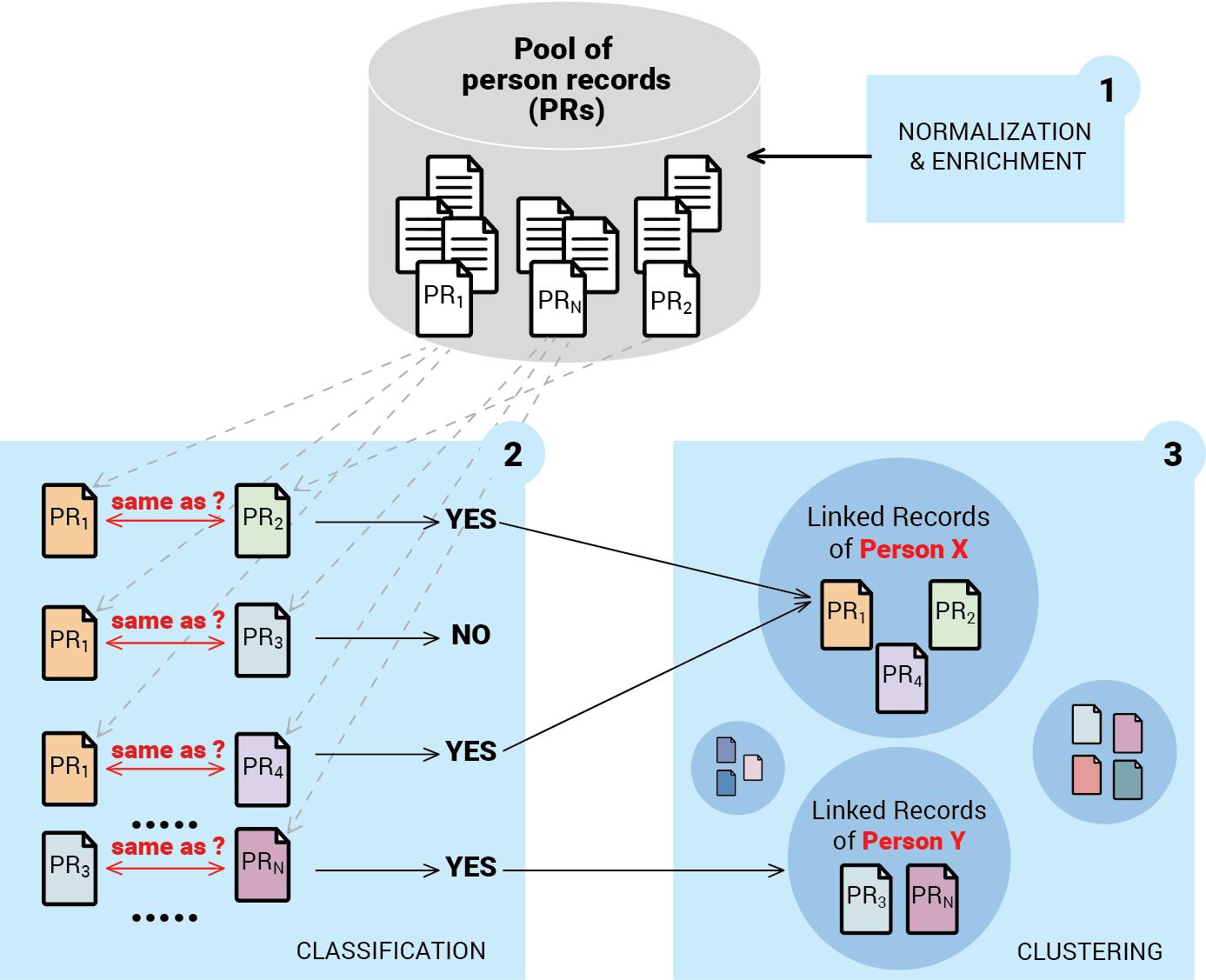
2.5 Linking and deduplication
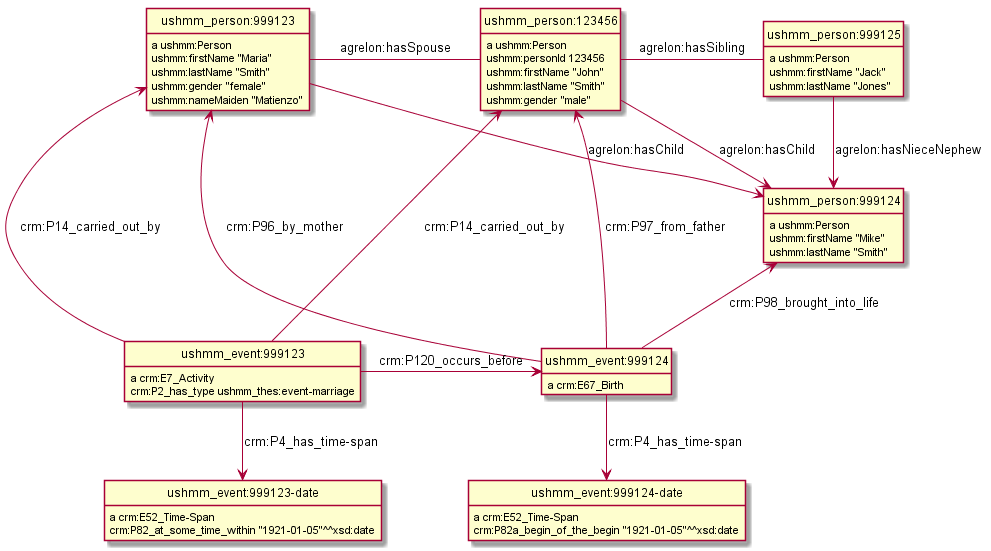
2.7 Peson networks model
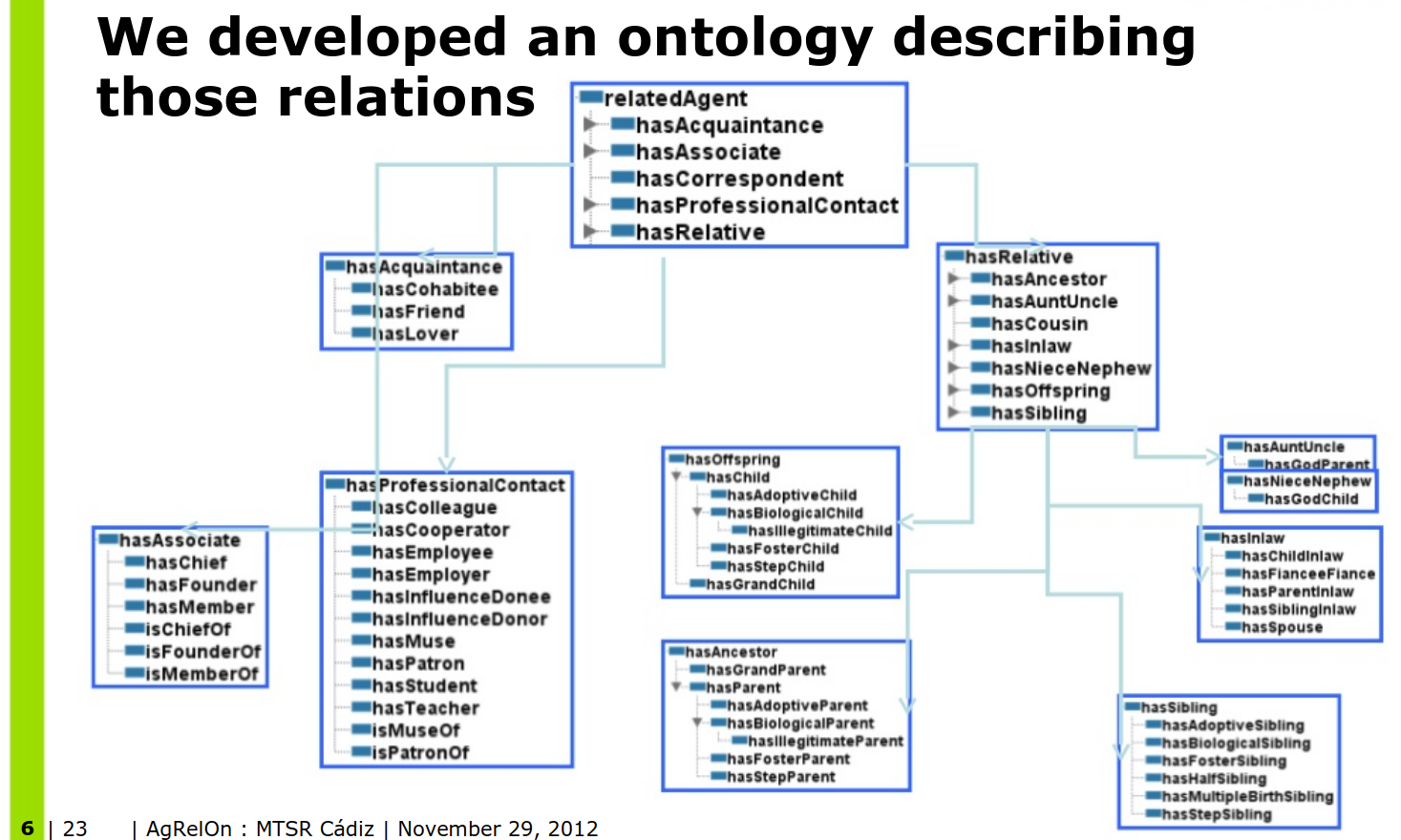
2.8 AgRelOn Ontology
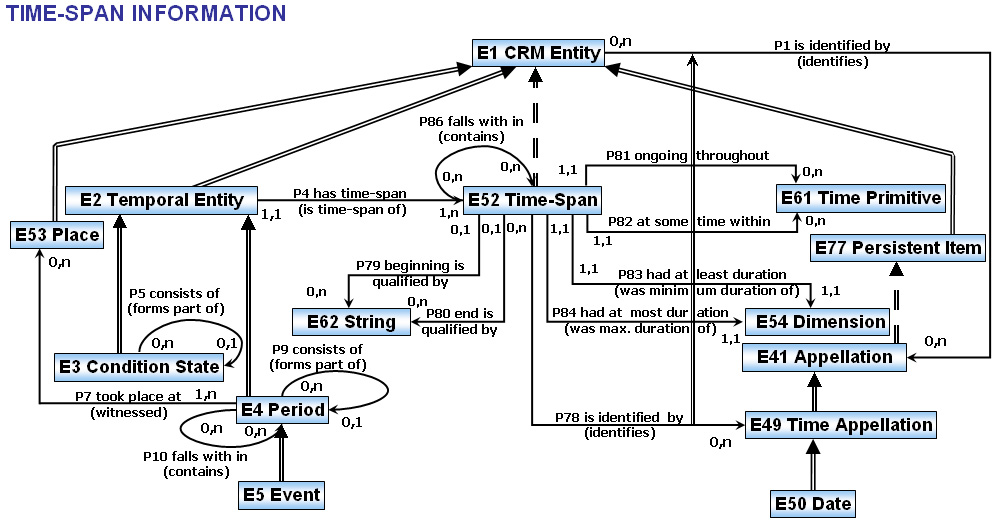
2.11 CIDOC-CRM temporal entity model
3.5 Indicator 14 Scientific Awards
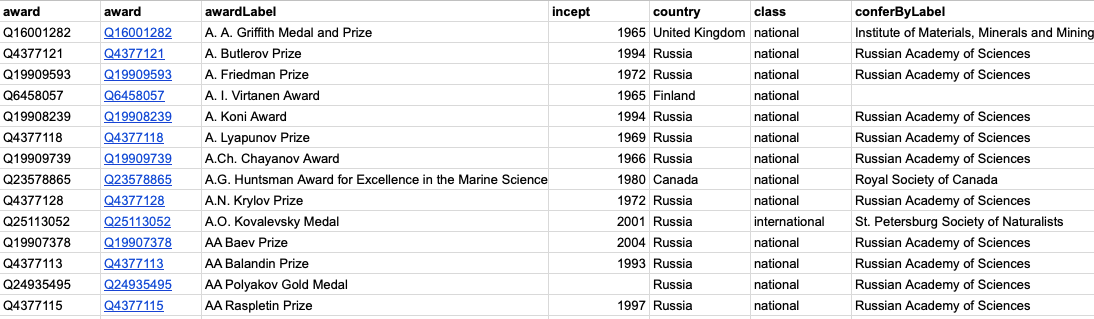
Gathering awards from Wikidata
- Wikidata had concentrated structured data about 1224 “science awards”
- Some awards did not have the appropriate Wikidata type (ex. “award” instead of “science awards”).
- Using the WP Category system we were able to add the correct type and extend the list to 1815 awards.
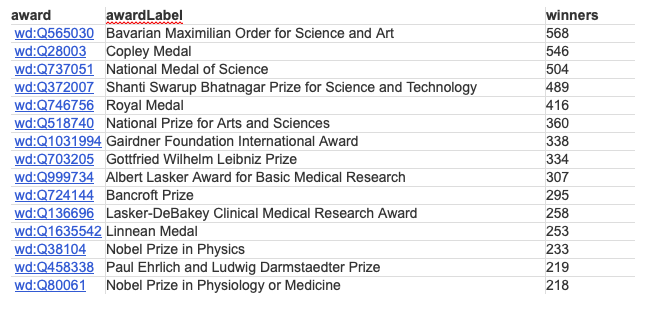
3.6 Award winners in WikiData
Wikidata also has info on award winners (27443 “wins” of 983 awards)
3.8 Petscan Interface
3.9 Adding weight to awards
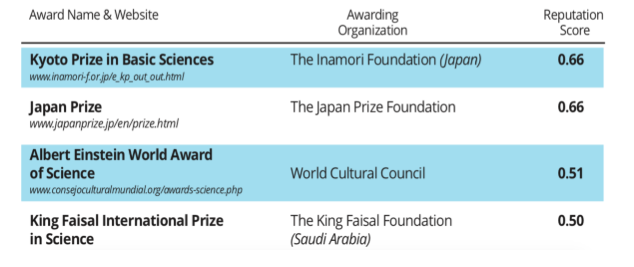
- The IREG Observatory’s list contains the most prestigious awards ranked by reputation score
- The PDF file needs has been converted into a table
- The data has been matched to the list of awards from Wikidata
- The reputation score has been added to Wikidata
4.1 Context and scope
(Open Source Intelligence) OSINT in the Banking sector A lot of cybersecurity related data is publicly available
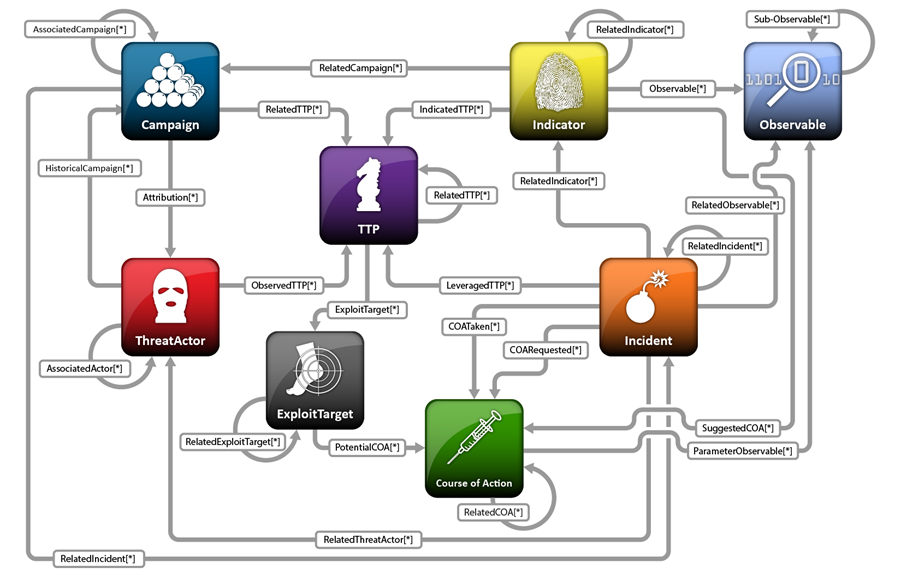
- Dedicated data model (STIX)
- Data providors - MITRE corp (WIKI and STIX)
- MISP galaxy - Github repo with fresh data
4.2 Unstructured data
- Cybersec reports in plain text
- Security corporations (Symantec, Kaspersky), Blogs etc..

4.4 Manual Annotation and textual classifcation task
- Manually annotate documents using Ontotext’s annotation tool
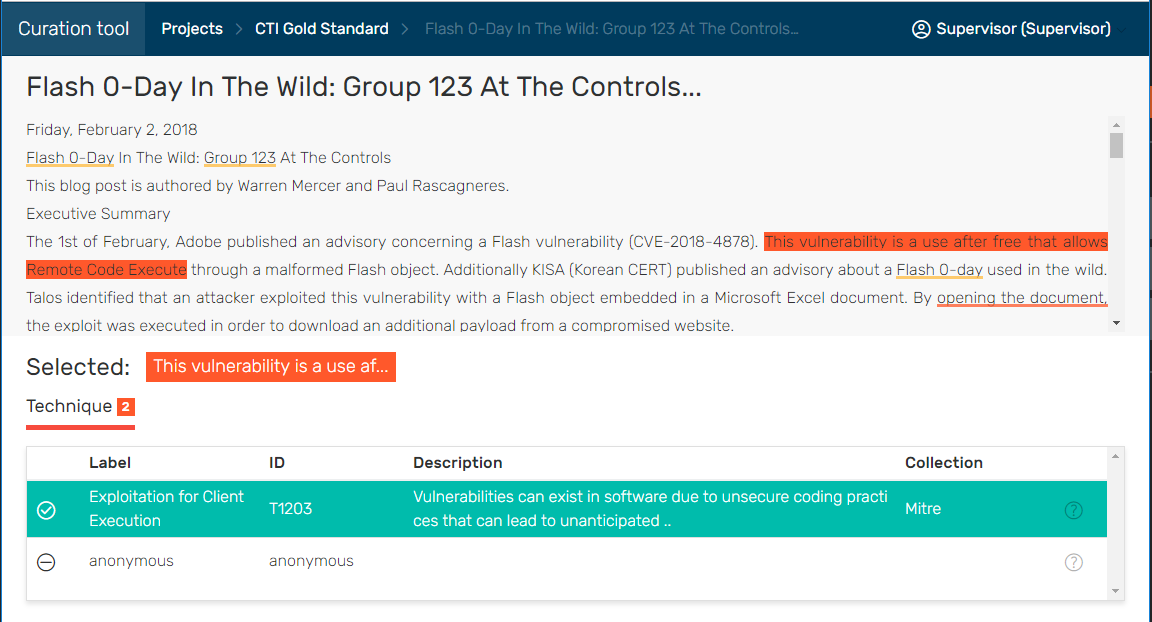
- Build a textual classification pipeline that predicts if a sentence is a mention of a “Technique” or “Tactic” class.
6.2 GraphDB
- Fast triplestore 100% W3C compliant
- Free version with very few limitations
- Excellent SPARQL editor
- Excellent ETL tools (OpenRefine integration)
- Fulltext search integration (Lucene, SOLR, Elastic)
- Very well documented
- Many more features
- Academic cooperation program
https://www.ontotext.com/products/graphdb/editions/
