How to Design a Successful SemTech PoC
2019-09-09
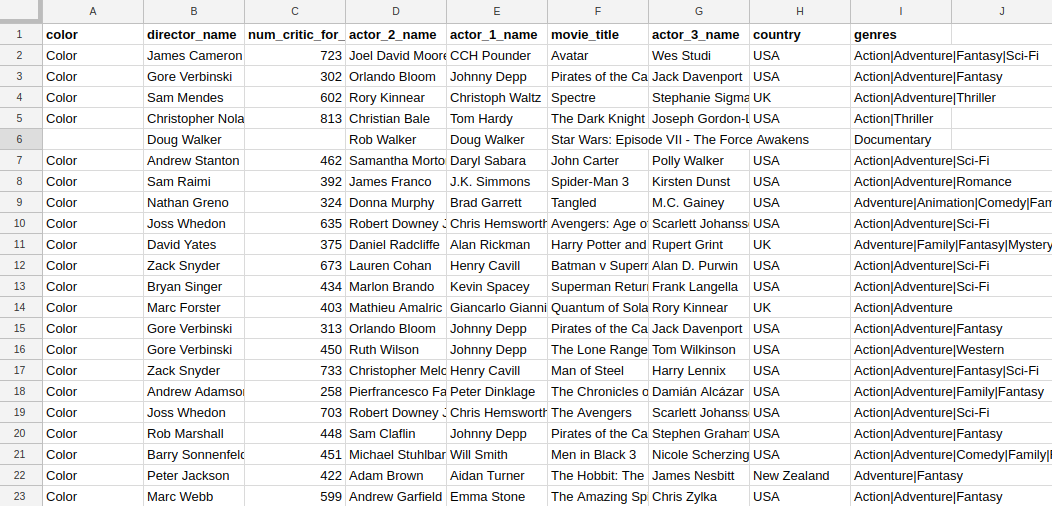
2.2 Simplified IMDB dataset
Our dataset is a simplified version of the public IMDB dataset
2.3 Sources for Semantic Integration: LOD Cloud

2.4 Sources for Semantic Integration: Datahub
2.5 Sources for Semantic Integration: Google Dataset Search

2.6 Sources for Semantic Integration: Google Cloud Public Datasets
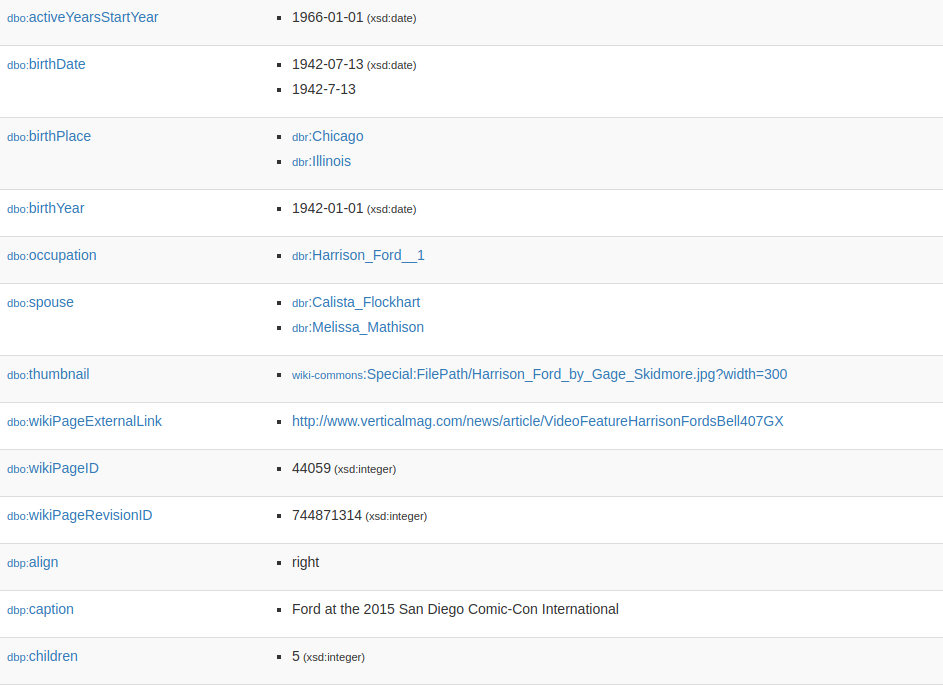
 ## Sources for semantic Integration: DBPedia
## Sources for semantic Integration: DBPedia
5.2 Normalise values
OntoRefine text facets allow quick bulk-editing of values
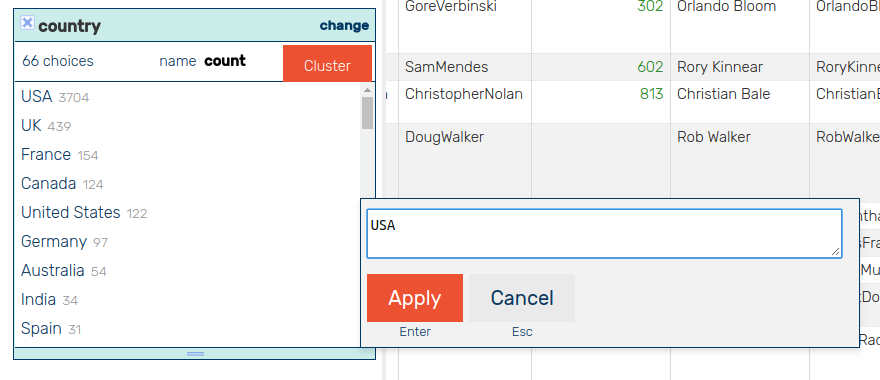
United States is normalised to USA in 122 cells
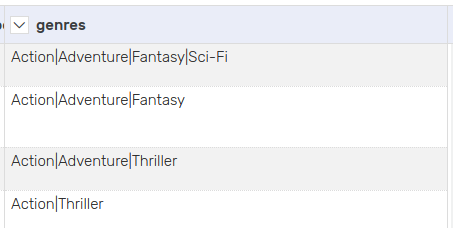
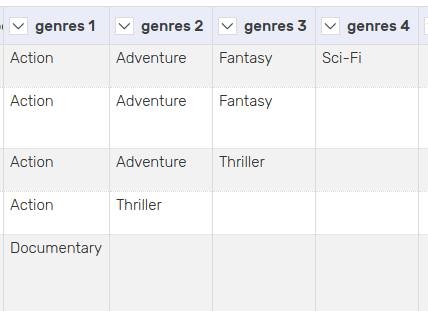
5.3 Create new columns
Split columns according to a separator character
5.4 Urlify
Edit the text in the cells
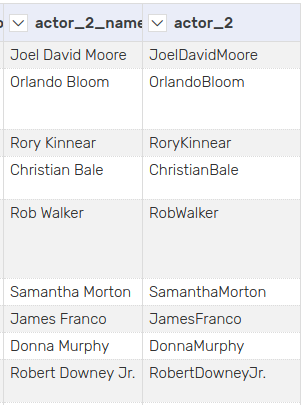
Remove whitespace so that the string can be used in a url/iri
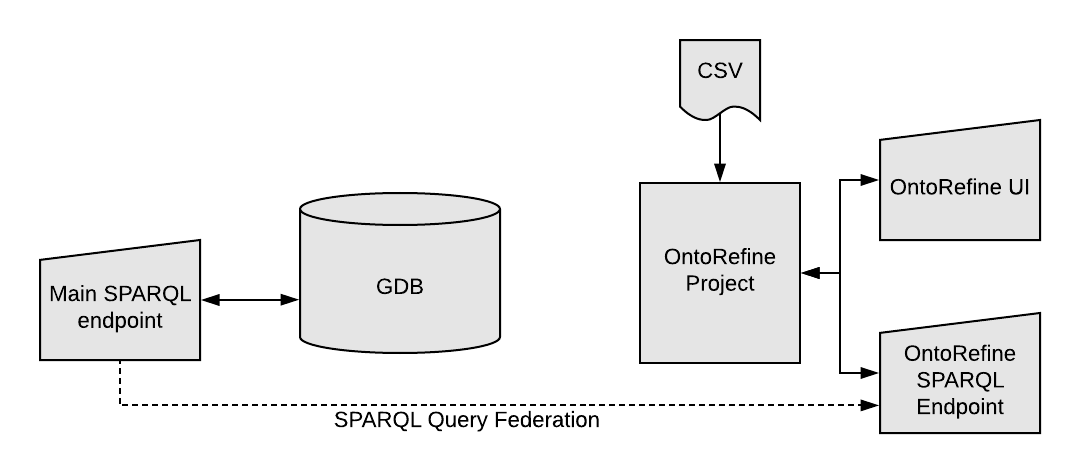
5.6 Tabular to Linked Data
Moving from tabular data to linked data
5.7 Tabular to Linked Data
Here is what our cleaned up table looks like…
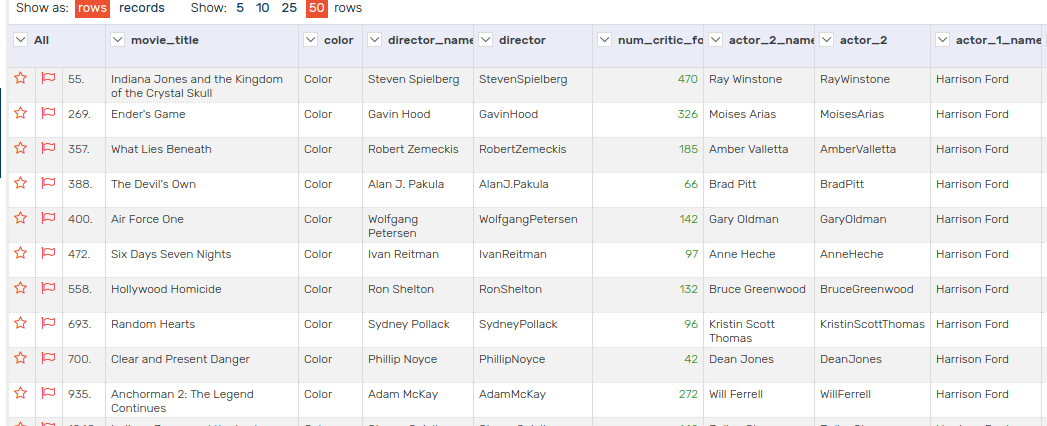
5.8 Tabular to Linked Data
… but here it is transformed into RDF.
5.9 Tabular to Linked Data
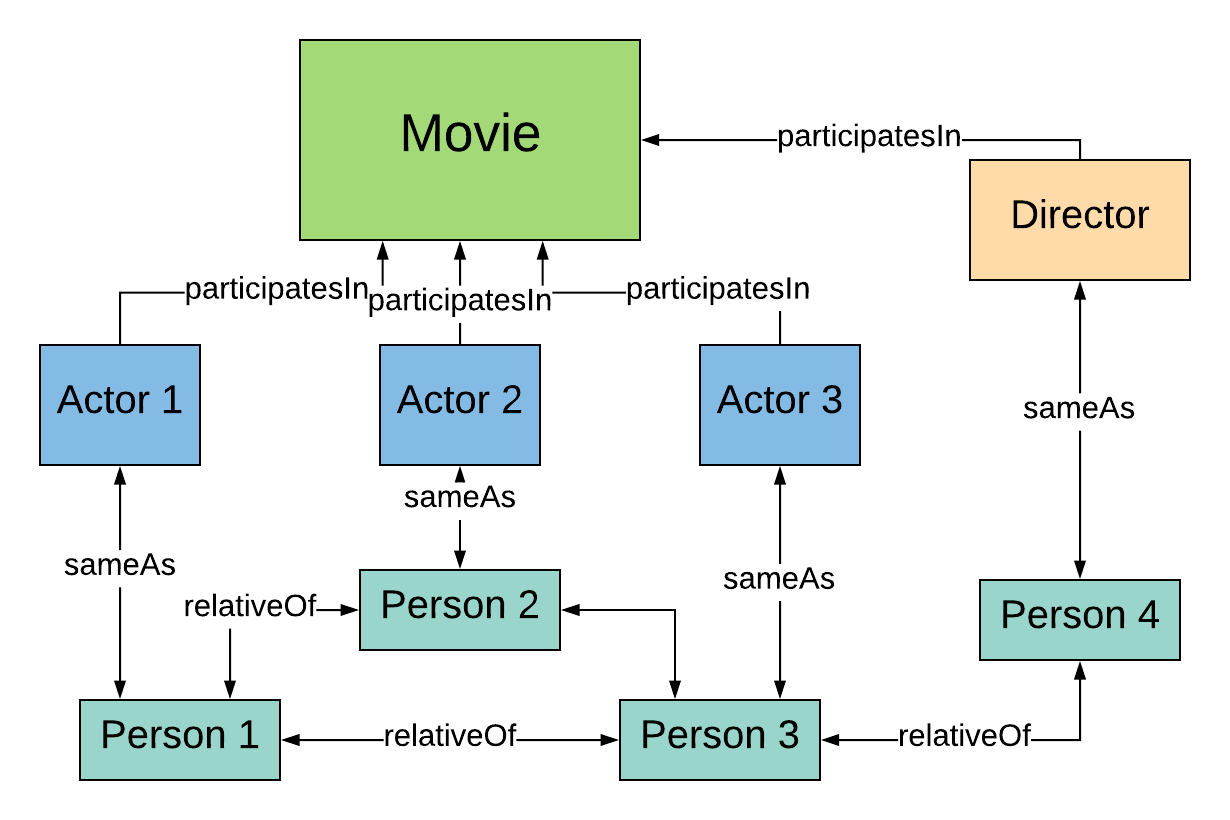
6.1 Initial data model
Output from our ETL procedure
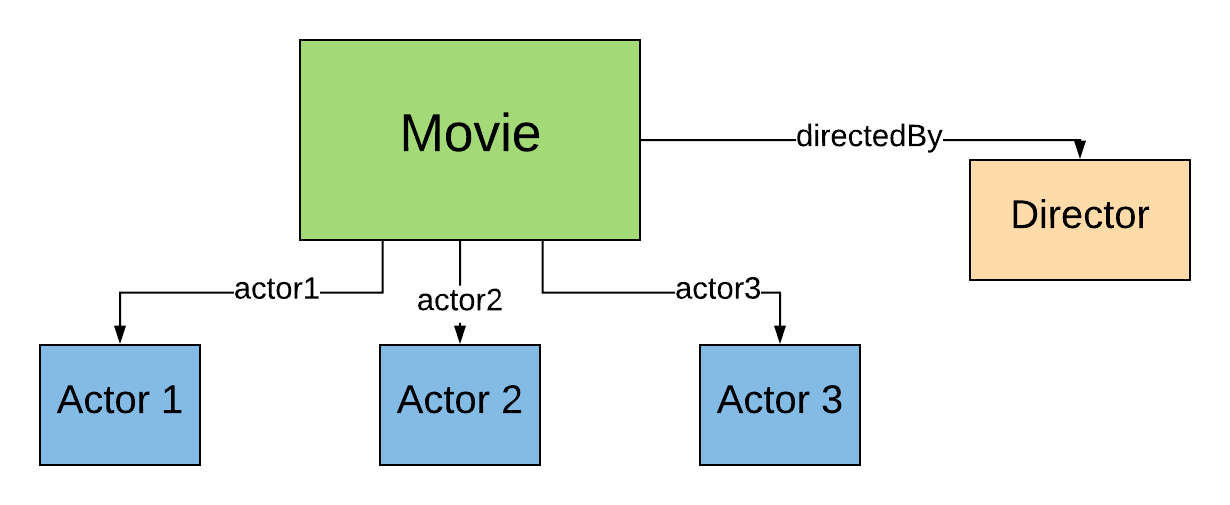
Does this model contain all the data we need?
6.2 Expanding the initial model
Incorporating data from an additional data source.
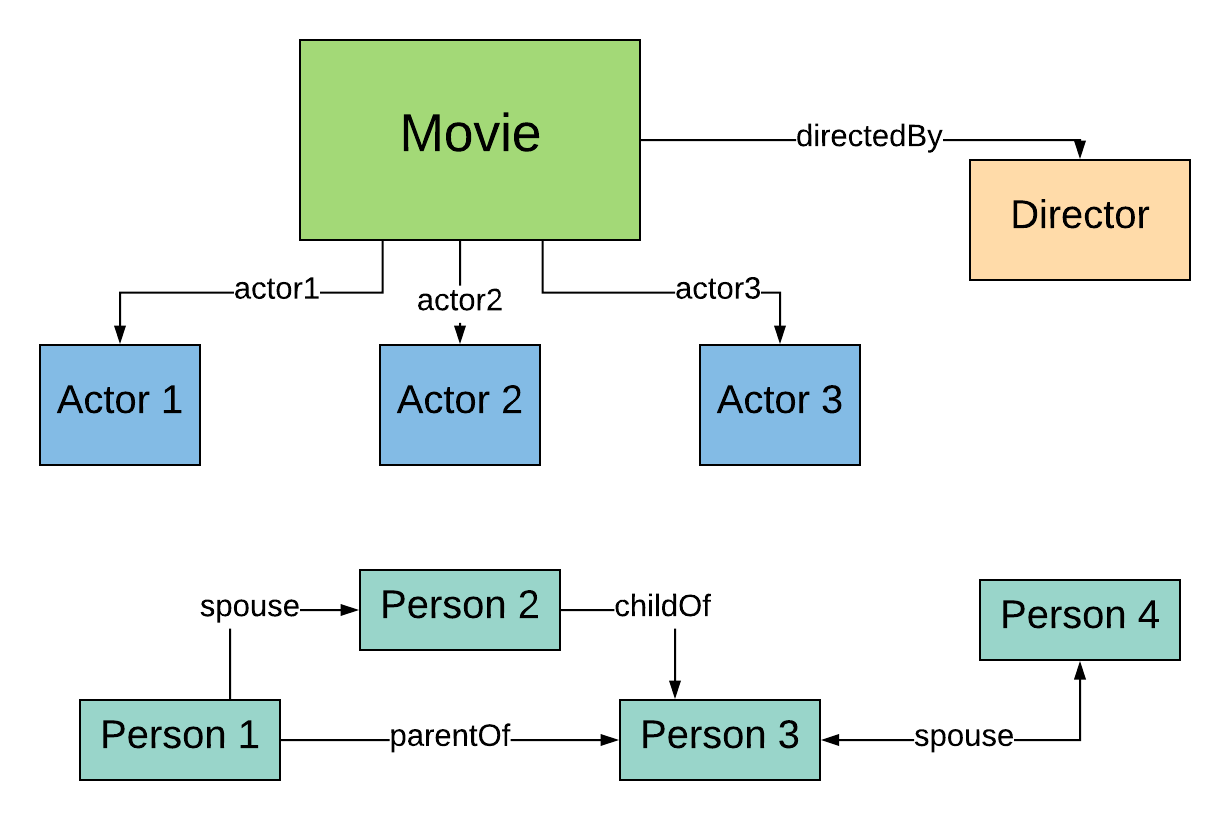
Can we simplify things?
6.3 Creating a new property
Single symmetric relation to use in a straightforward manner.
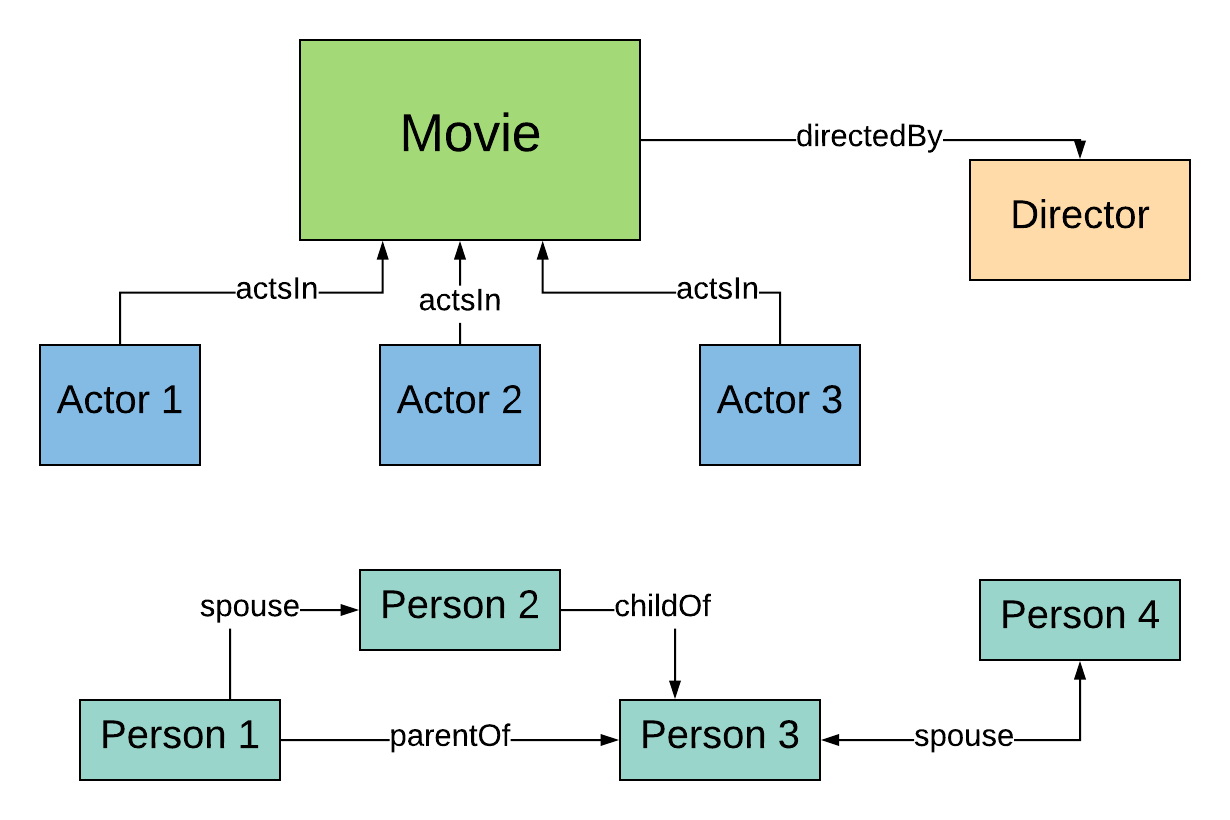
Can we simplify things further?
6.4 Creating a second new property
Three relations transformed into a single one.
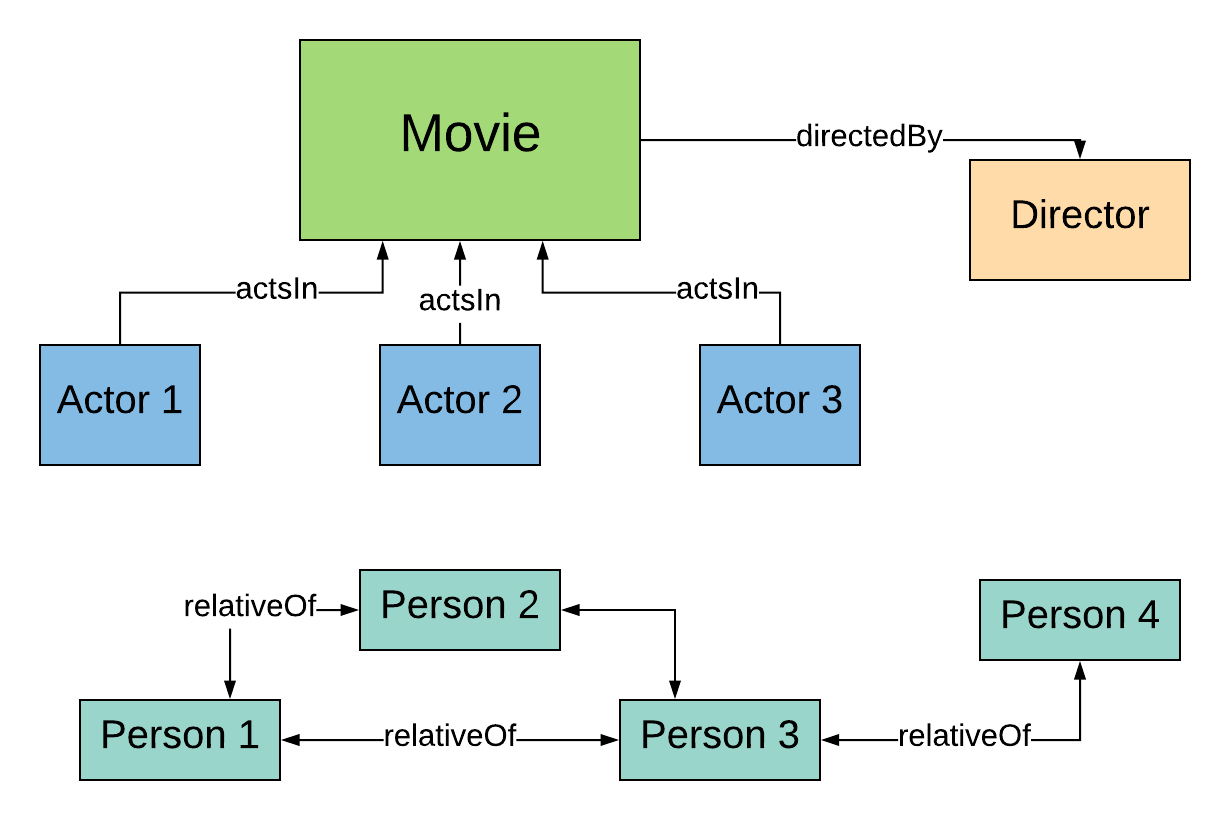
But we are still working with two disconnected parts.
6.5 Connecting the dataset
Now we have everything we need to ask our question.
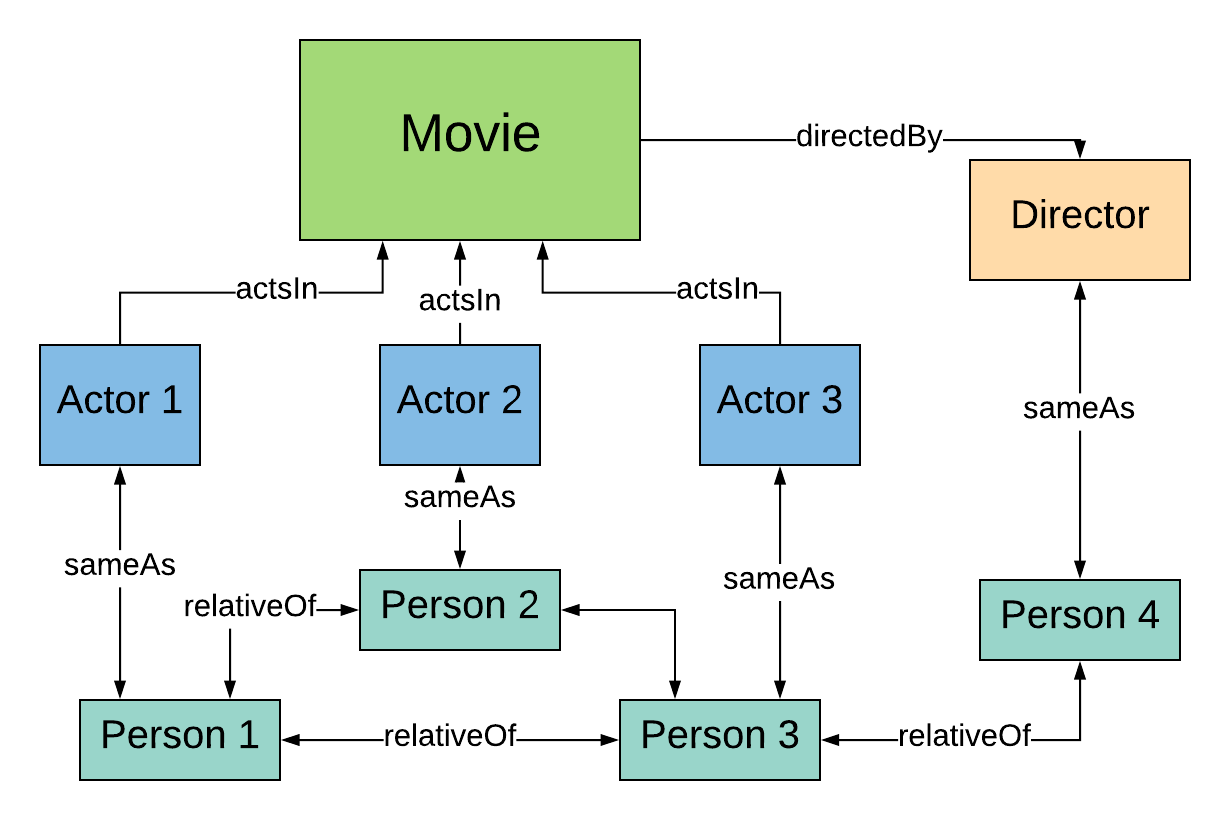
What if we want to ask a more complex question?
6.6 Changing the model
At later stages we can rework the model which will then require corresponding changes to the procedure.
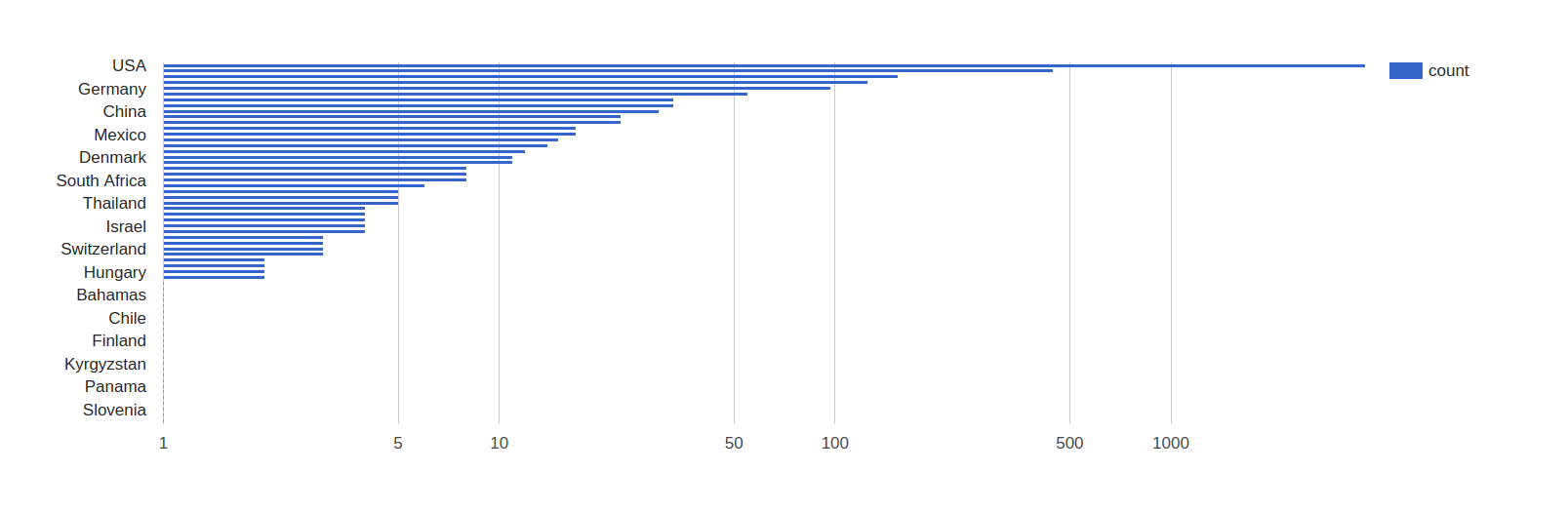
7.1 Google charts
Visualize data in google charts in GDB
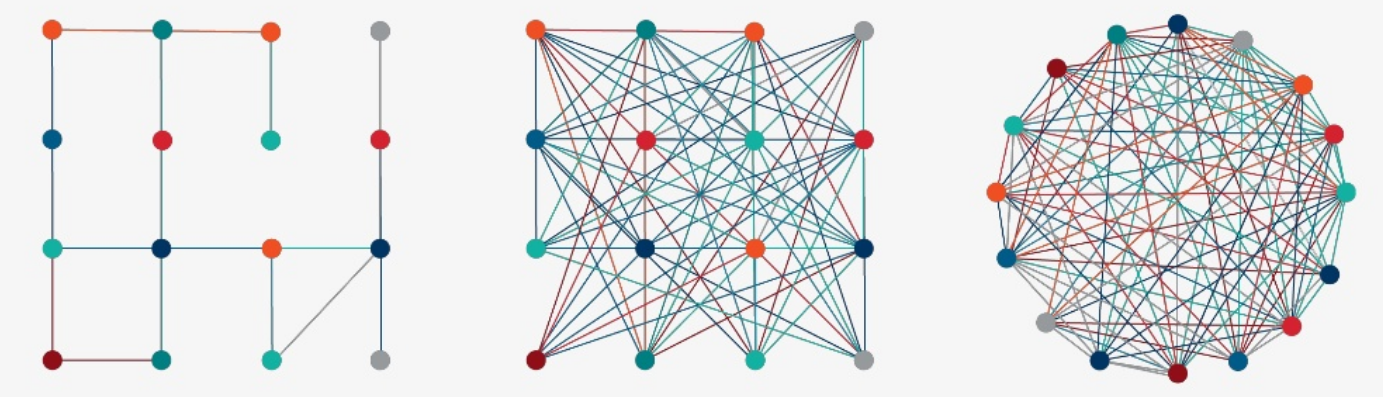
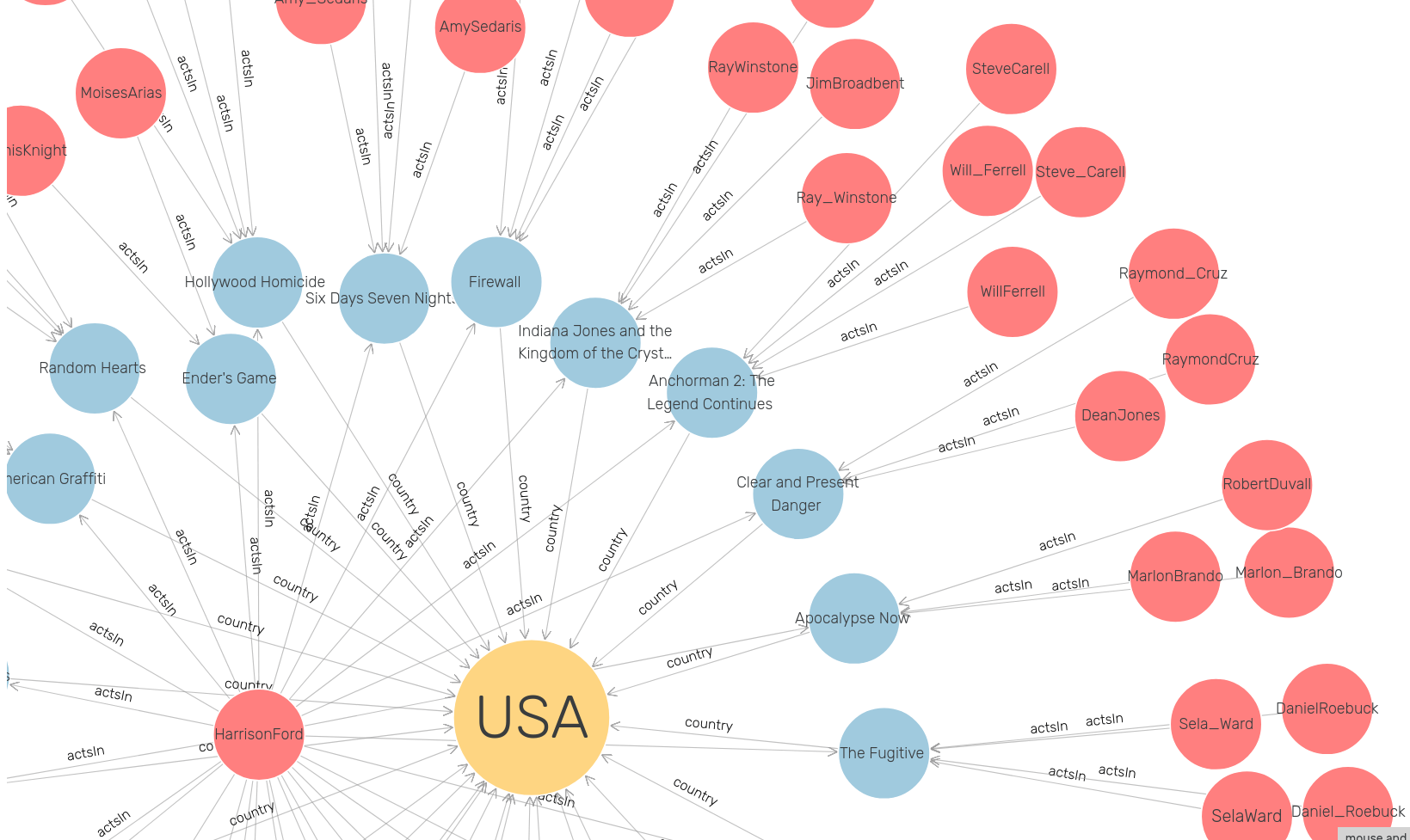
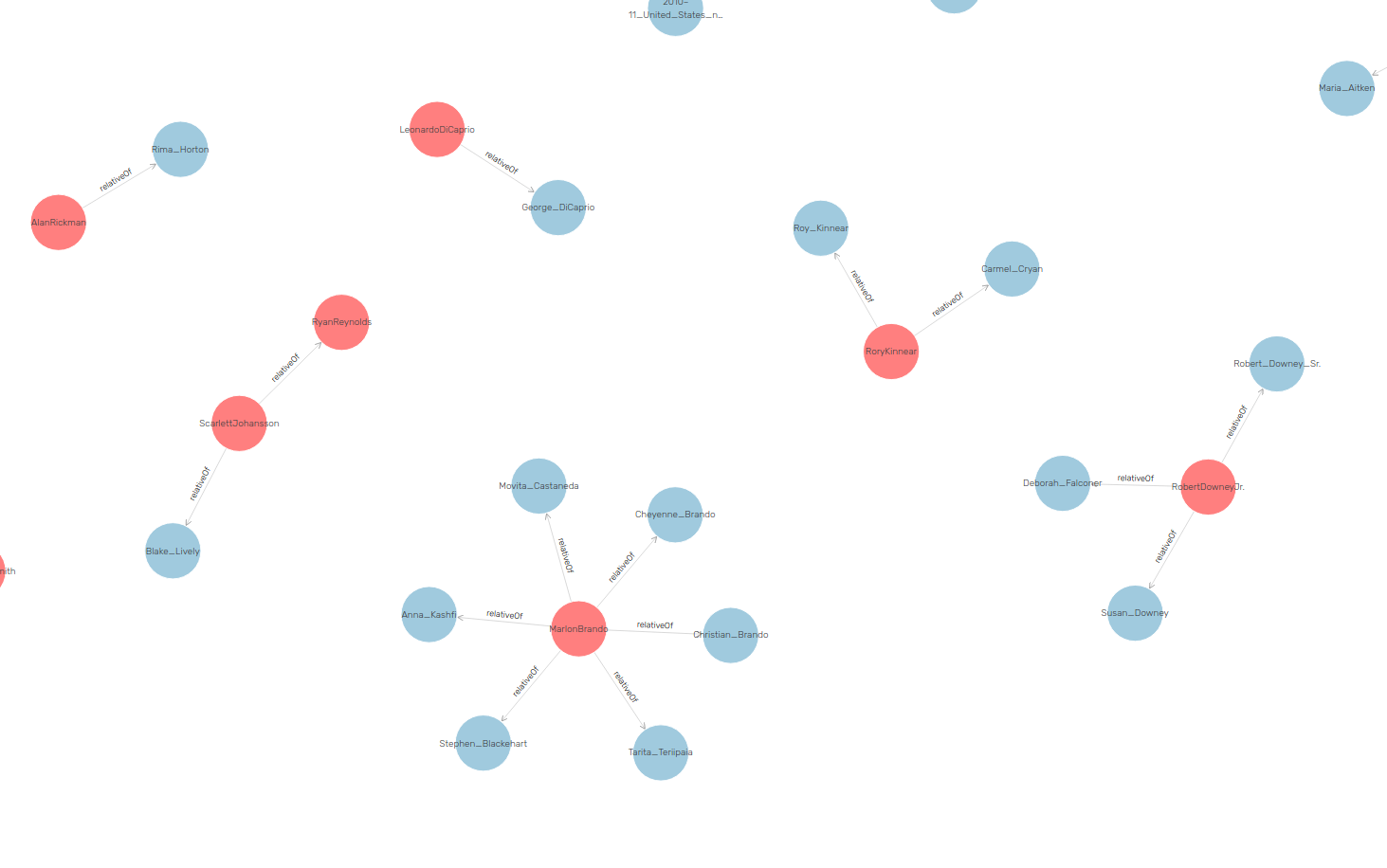
7.2 Visual graph
Highly configurable network visualisation using SPARQL
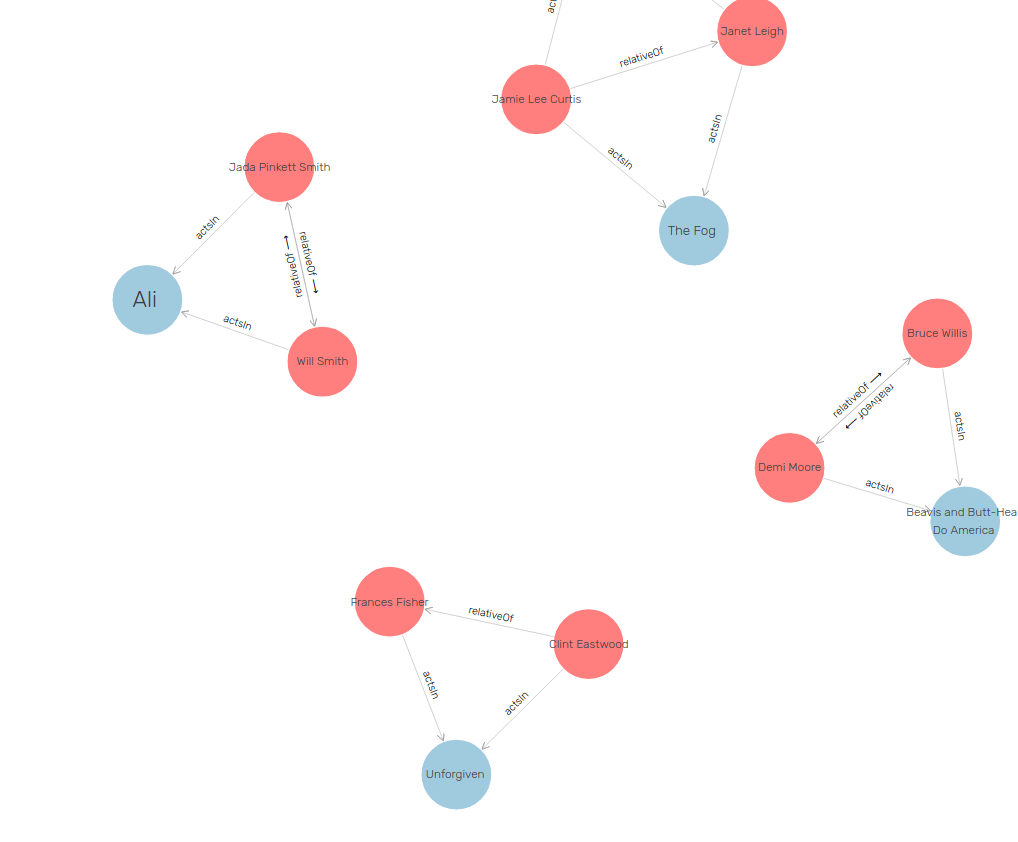
7.3 Visualize family Relations
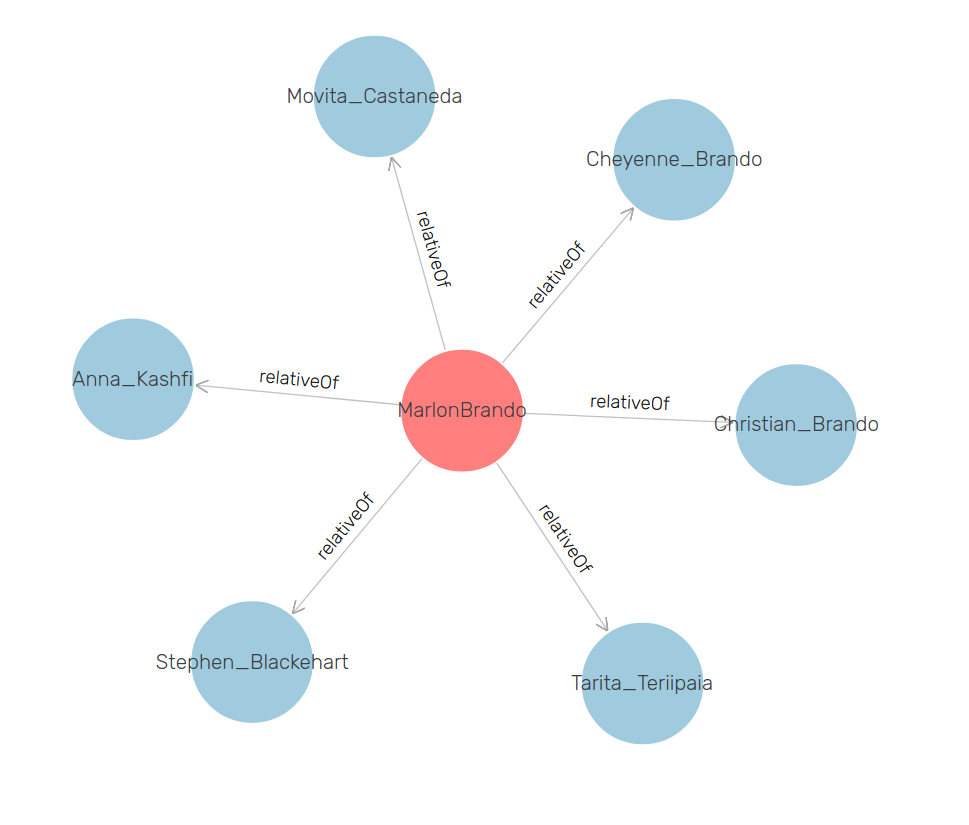
7.4 Visualize family Relations 2
7.5 Is there nepotism in Hollywood?
11.4 Questions
