Semantic Data Integration and the Linked Data Lifecycle
2019-03-12
0.1 Introduction
- Semantic Data Integration is a lot more than Ontology Engineering:
- Dataset research
- Data analysis
- Data cleaning
- Semantic model: examples, shapes, documentation
- Ontology engineering
- Data mapping/conversion (ETL)
- Instance matching/reconciliation
- Data fusion/harmonization
- Semantic text/metadata enrichment
- Data enrichment, inference, aggregation
- Sample queries
- Semantic search, apps, visualizations
0.2 How Does This Differ from Data Warehousing?
- Semantic databases (Knowledge Bases or Knowledge Graphs) are self-describing
- Data warehousing usually focuses on statistical data (OLAP)
- KGs can represent OLAP using the W3C Cube ontology, but can also represent any other kind of data
- There are vast LOD datasets that can be utilized in building KGs
- Everyone seems to be building a KG!
0.3 Example
Google KG: Entity Pages, Disambiguation
0.4 Competence Questions
- Before developing applications, one better develop business requirements
- Before procuring/integrating data, one better develop competence questions
- These are sample questions that the KG should be able to answer
- They should lead both dataset research and semantic modeling
1 Dataset Research
- Given a data goal (competence questions), what datasets are available and relevant?
- What is the enterprise data that we “intuitively” know should be captured?
- Are there data gaps compared to the competence questions? How can we fill them?
1.1 How to Find Datasets?
- Wikidata’s
external-idprops are an excellent source (over 3700) - A lot of them have corresponding Mix-n-Match catalog
- A lot are potentially applicable to GLAM, eg Authority control for people 510, Identifier 196, Authority control 102, Authority control for artists 59, Cultural heritage identification 34, etc
- Wikipedia categories and Related links
- https://datahub.io and https://old.datahub.io
- http://lod-cloud.net
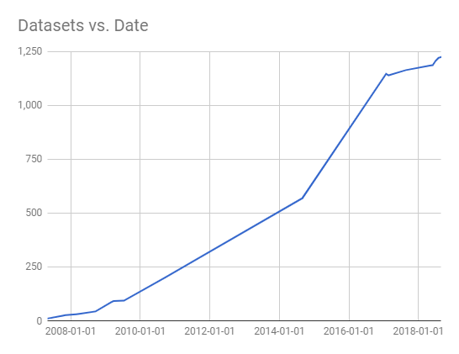
1.2 LOD Cloud
The Linked Open Data (LOD) Cloud contained 28 datasets in 2007

1.3 … 89 datasets in 2009 …

1.4 … 295 datasets in 2011 …

1.5 … 570 datasets in 2014 …

1.6 … 1234 datasets today!

16136 links between datasets, 30B triples
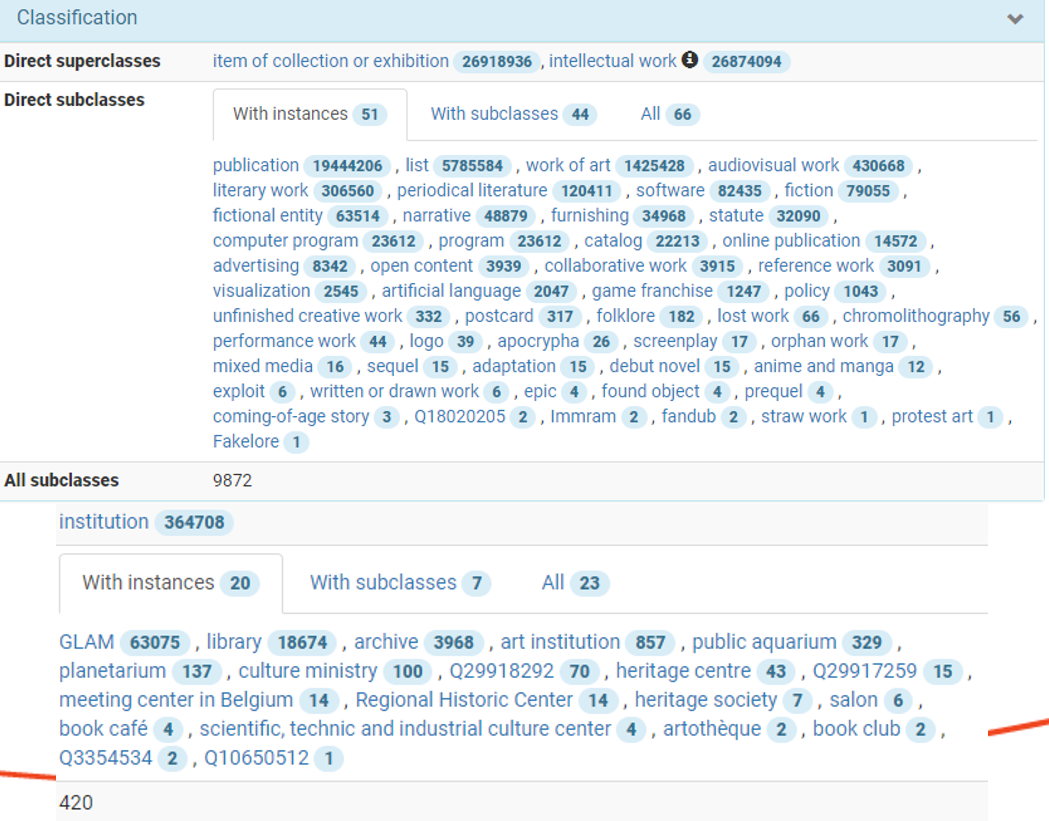
1.7 Wikidata
Number of Creative Works and Cultural Institutions in Wikidata:
1.8 Finding Data
- By Example:
- Eg to find computer science awards, get a famous computer scientist (eg Tim Berners-Lee) and explore his awards
- Eg to find artist biographic info, get a well-known artist (eg Emily Carr), find mentions of her on the web, list the ones that provide good biographic text
- Knowledge and experience helps
- Keep abreast of LOD developments in your domain
- Read papers, especially in the SWJ http://www.semantic-web-journal.net/accepted-datasets
2 Dataset Analysis
2.1 Scope
- Feasibility estimations confronting the data with the use cases.
- Familiarisation with the data
- Size and complexity estimations of the data are performed
- The data is comprehensively understood
- Exceptional values are extracted and analyzed
- Cardinalities are extracted and analyzed
- The tools for the later phases are chosen
- General feasibility is estimated
- The groundwork for the mapping component of ETL is laid down
2.2 Key Value Analysis
- Key values that often drive the mapping. Key-values could be mapped to:
- Individual (eg
skos:Concept) - Class
- Property
- or can even dictate a mapping decision, eg one mapping branch for Persons, another for Organizations
- Individual (eg
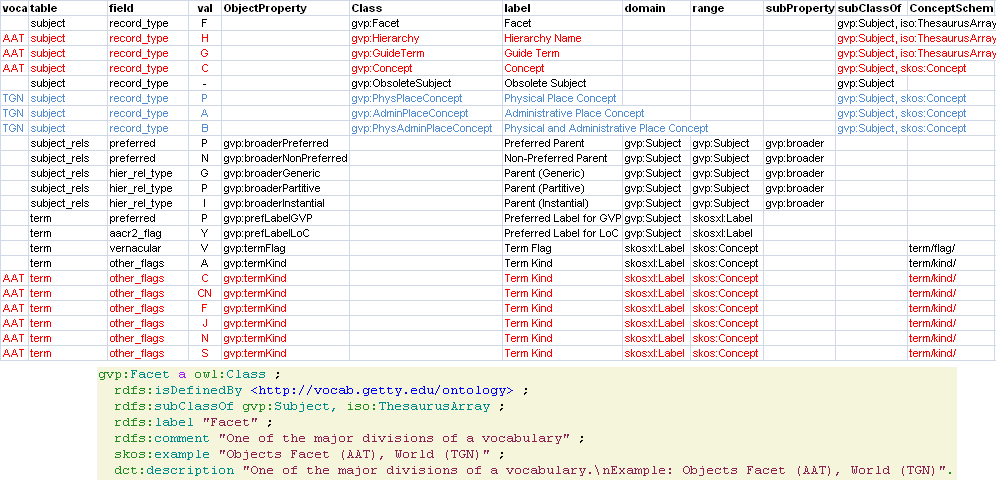
2.3 Key Value Example
Frоm Getty LOD - “Excel-driven Ontology Generation™”
2.4 Data Coverage
Example: PubMed Field Statistics
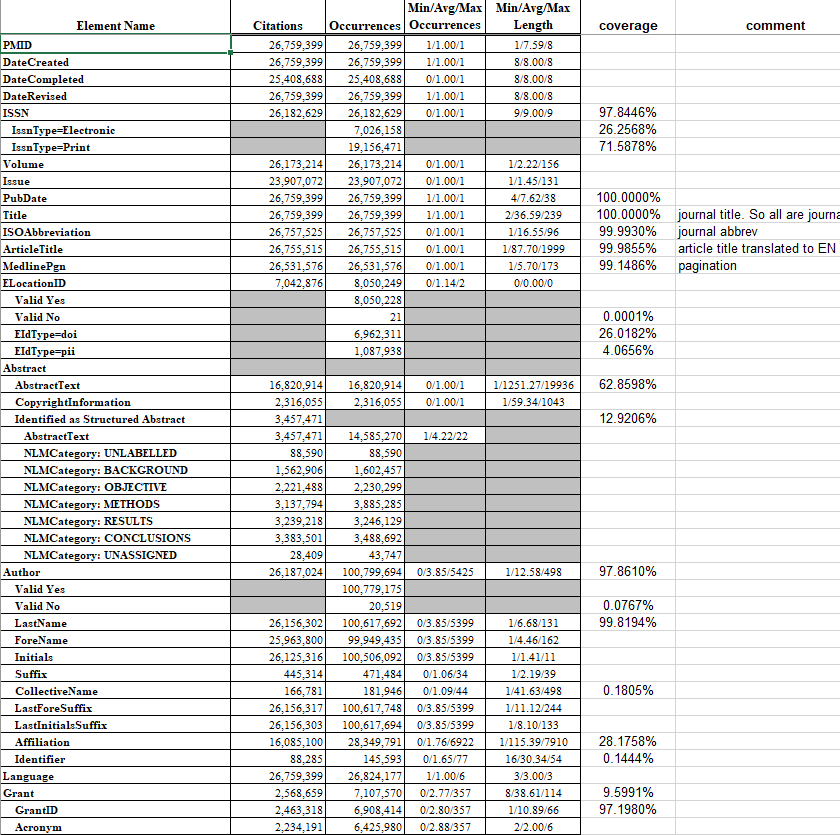
2.5 Data Quality
- Coverage assessment dictates what is worth converting
- Quality assessment drives data cleaning needs and decisions
3 Data Modeling
3.1 Scope
- Create a data model for the domain of interest
- Find existing relevant ontologies to use
- Add custom classes and properties as needed (Ontology Engineering)
- Document the model comprehensively: describe modeling patterns, justify decisions
- Document in machine-readable way using RDF Shapes (SHACL or ShEx)
- Make examples that can drive (generate) other artifacts, eg example diagrams, shapes
3.2 URL Design
- “URL Design” is something simple yet fundamental to RDF and LOD.
- It’s a fundamental part of TimBL’s 5-Star Linked Data principles: CoolUri’s don’t change, Cool URIs for the Semantic Web
- Well-designed URLs enable highly distributed ETL development and execution
- Experience shows that leaving URL design to ETL devs is not a good idea: unspecified URLs cause disconnected data
- Platts URL Design (internal document, could be shared)
- Getty doc on URLs
3.3 Existing or New Ontology?
Pros:
- Reuse as much as possible
- This will save you time, and will make your data more easily reusable
- Search for ontologies: Linked Open Vocabularies
Cons:
- Multiple namespaces make data production/consumption a bit harder
- Schema.org is the ultimate “chauvinistic” example: single namespace, and even extensions (eg GoodRelations or SchemaBibEx) land in the same namespace.
- I guess webmasters like the simplicity (and still often get it wrong ;-)
- Don’t reuse a complex ontology for a single term (heavy ontology baggage)
- Consider reusing ontology terms, but not necessarily loading the ontology
- Example: every
dct:property is a subprop ofdc:, and such inference may be useless to you
- Example: every
3.4 Ontology Methodologies
How to do ontology engineering?
- Avoid it if you can (i.e. reuse ;-)
- Competence Questions !
- Methods such as DILIGENT, METHONTOLOGY, NeON Methodology, ROO Kanga, SAMOD (Simplified Agile Methodology), HCOME (Human-centered ontology method), Aspect OntoMaven (Aspect-Oriented Ontology Development), IDEF5, ONTOCOM (cost estimation)
- Ontology Design Patterns: typical situations. Composable!
- Top-level ontologies: BFO, CCO, DOL/DOLCE, SUMO, UFO, Proton…
- For cultural heritage: CIDOC CRM, ConML/CHARM
4 Data Conversion (ETL)
4.1 Scope
- Transformation and homogenization of data sources into the target format, in order to populate the semantic model with instances
- Important elements:
- Choice of tools in accordance with the need and requirements
- Maintainability of the solution
- Reproducibility / exportability / portability
- Data cleaning
- Other Considerations:
- formats
- size scale (tools parse in memory)
- consistency with existing conventions (project, sector)
4.2 Example
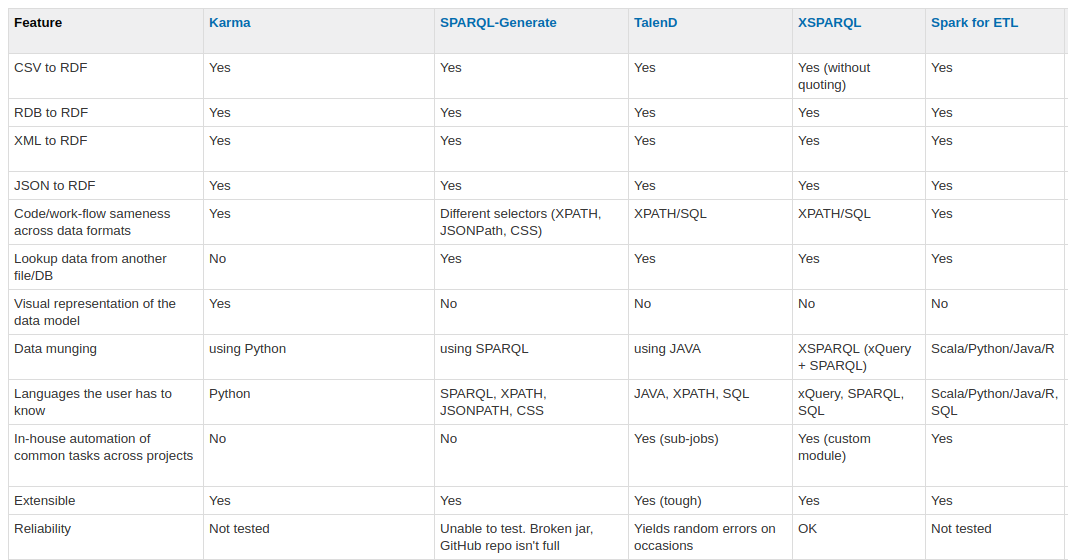
Onto ETL tools evaluation
5 Validation
5.1 RDF Shapes
TODO links
- ShEx: W3C community spec. Pros: much briefer (compact, JSON and RDF representations), allows recursive data models, flexible focus nodes (shape map).
- SHACL: W3C standard. SHACL-core and SHACL-standard. Advanced Features is a community spec. Pro: standardizes validation results
- Validating RDF book (reviewed by Ontotext)
- Implementations at Validating RDF wiki): summarized at next slides, but see the link for more details!
5.2 ShEx Implementations
| name | language | playground, source, distribution |
|---|---|---|
| shex.js | js | http://rawgit.com/shexSpec/shex.js/master/doc/shex-simple.html, https://github.com/shexSpec/shex.js/ |
| ShEx NPM | js | https://www.npmjs.com/package/shex |
| ShEx-validator | js | https://github.com/HW-SWeL/ShEx-validator |
| Validata | js | http://hw-swel.github.io/Validata/, https://www.w3.org/2015/03/ShExValidata/, https://github.com/HW-SWeL/Validata |
| ShExJava | java | http://shexjava.lille.inria.fr/, https://github.com/iovka/shex-java, https://gforge.inria.fr/projects/shex-impl/ |
| RDFShape, ShaclEx | scala | http://rdfshape.weso.es/, http://shaclex.herokuapp.com/, https://github.com/labra/rdfshape, https://github.com/labra/shaclex |
| TrucHLe | scala | https://github.com/TrucHLe/SHACL |
| PyShEx | python | https://github.com/hsolbrig/PyShEx |
| shex.rb | ruby | https://github.com/ruby-rdf/shex |
| ShExkell | haskell | https://github.com/weso/shexkell |
5.3 SHACL Implementations
5.4 Custom Test Suites
- RDFUnit (source, demo): sources custom patterns, OWL, OCLS shapes, DC Application Profiles, SHACL
- Only SPARQL queries
- negative examples
- SPARQL queries and example output
- Compares output of a query to the desired output
- Could test data and/or the queries themselves
- Domain Specific-Validation
- Eg for SKOS: qSKOS, Sparna SKOS Tester
6 Text and data enrichment
6.1 Scope
Semantic enrichment is the adding of value to a dataset by increasing the amount of queryable information it contains and/or decreasing the data’s noisiness. This is done in several ways:
- Inference and link discovery
- Thesaurus harmonisation
- Entity mining
- Instance matching and deduplication.
- Data fusion
6.2 Inference and link discovery
- Inference : Attributes and relations are added based on rules.
- Link discovery. The structure and redundancies of the graph are exploited in order to discover new relations between entities (graph based ML)
- Subgraph similiarity to infer new links
- e.g Facebook friend recommendations
- e.g Amazon product recommendations
6.3 Thesaurus harmonisation
6.4 Entity mining.
- Unstructured data (text, images) is processed in order to extract novel entities and relations and add them to the dataset.
- Content classification
- Attribution of categories to text, images or sound clips
- Statistical methods
- e.g e-mail filters
- Attribution of categories to text, images or sound clips
- NLP Named entity recognition (NER)
- Ontotext NOW and TAG,
- Google NLP, etc
- Relation extraction from text
- NER + relations between entities
6.5 Data fusion.
Redundant data is deduplicated and fused to produce a single master dataset without conflicts. selection of representative single fields (eg logo), * accumulation of multiple fields (eg names, transactions), * aggregation of summary fields (eg count or total amount)
6.6 Matching
- Critical problem in data cleaning and integration
- Overlapping instances across multiple datasets (client only or client and LOD) are matched and the sum of their attributes across datasets become available for querying.
- Entity matching (EM) finds data instances that refer to the same real-world entity
- We focus on EM as a process of transforming a string to a thing based on the provided semantic context
6.7 Basic Reconciliation
- Fuzzy name matching
- Simple additional features (e.g. exact string matches, differences in numbers)
- Out-of-the-box match scoring & available recon services
- Openrefine, Ontorefine
- wikidata recon service
- reconcile-csv - build-your-own
## Advanced Reconciliation
- Custom field parsing and normalization - additional parsing rules (acronyms, titles, dates etc)
- Complex additional features
- text analysis
- hierarchical features
- geographical features
- network topology
- Custom match scoring (possibly deep learning) e.g deep siamese text similarity
7 Modelling update flows
8 Model documentation
8.1 Scope
- Data Diagrams
- Detailed description of both new ontology terms (classes and properties) and reused ones (describing the specific use in our application profile).
- Reference documentation
- Generated by an ontology documentation tool
- Hand written comprehensive doc
- Generated by an ontology documentation tool
- Semantic publishing of model
- Sample Queries
8.2 Sample queries
- Very handy way to augment the documentation
- Can be used by a new user to get a feel of the data
- Highly informative when combined with a short description
- Stem out of competence questions
- Can be used for testing purposes
- Eg GVP sample queries
9 Semantic search apps and visualizations
9.1 Semantic Search
- Search for concepts rather than strings TODO nice example
9.2 Visualizations
- GDB Visual Graph
- Wikidata Viz page
- Neo4j Graph Database Platform Graph V-Day recap
